

Barry Pollard from Google did a long explanation on Bluesky on why Google Search Console says an LCP is bad but the individual URLs are fine. I don't want to mess it up, so I will copy what Barry wrote.
Here is what he wrote across several posts on Bluesky:
Core Web Vitals mystery for ya:
Why does Google Search Console same my LCP is bad, but every example URL has good LCP?
I see developers asking: How can this happen? Is GSC wrong? (I'm willing to bet it is not!) What can you do about it?
This is admittedly confusing so let's dive in...
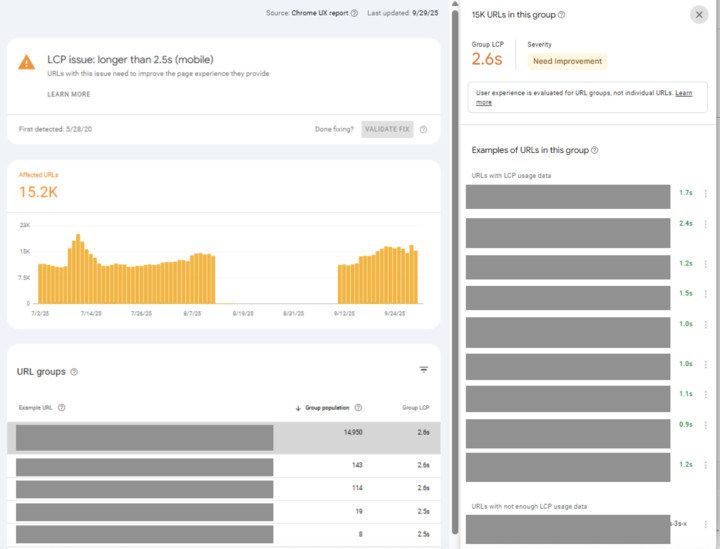
First it's important to understand how this report and CrUX measures Core Web Vitals, because once you do, it's more understandable, though still leaves the question as to what you can do about this (we'll get to that).
The issue is similar to this previous thread:
"How is it possible for CrUX to say 90% of page loads are good, and Google Search Console to say only 50% of URLs are good. Which is right?"
It's a question I get about Core Web Vitals and I admit it's confusing, but the truth is both are correct because they are different measures...
1/5 🧵
— Barry Pollard (@tunetheweb.com) August 19, 2025 at 6:32 AM
CrUX measures page loads and the Core Web Vitals number is the 75th percentile of those page loads.
That's a fancy way of saying: "the score that most of the page views get at least" — whee "most" is 75%.
Philip Walton covers it more in this video:
For an ecommerce site with LOTS of products, you'll have some very popular products (with lots of page views!), and then a long, long tail of many, many less popular pages (with a small number of page views).
The issue arises when the long tail adds up to be over 25% of your total page views.
The popular ones are more likely to have page-level CrUX data (we only data when we cross a non-public threshold) so are the ones more likely to be shown as examples in GSC because of that.
They also are the ones you probably SHOULD be concentrating on—they are the ones that get the traffic!
But popular pages have another interesting bias: they are often faster!
Why? Because they are often cached. In DB caches, in Varnish caches, and especially at CDN edge nodes.
Long tail pages are MUCH more likely to require a full page load, skipping all those caches, and so will be slower.
This is true even if the pages are built on the same technology and are optimised the exact same way with all the same coding techniques and optimised images...etc.
Caches are great! But they can mask slowness that is only seen for "cache misses".
And this is often why you see this in GSC.
So how to fix?
There is always going to be a limit to cache sizes and priming caches for little-visited pages doesn't make much sense, so you need to reduce the load time of uncached pages.
Caching should be a "cherry on top" to boost speed, rather than the only reason you have a fast site.
One way I like check this is to add a random URL param to a URL (e.g. ?test=1234) and then rerun a Lighthouse test on it changing the value each time. Usually this results in getting an uncached page back.
Compare that to a cached page run (by running the normal URL a couple of times).
If it is a lot slower then you now understand the difference between your cached and uncached and can start thinking of ways to improve that.
Ideally you get it under 2.5 seconds even without cache, and your (cached) popular pages are simply even faster still!
Incidentally, this can also be why ad campaigns (with random UTM params and the like) can also be slower.
You can configure CDNs to ignore these and not treat them as a new pages. There's also an upcoming standard to allow a page to specify what params don't matter:
This is cool and been waiting for No-Vary-Search to escape Speculation Rules (where this was originally started) to the more general use case.
This allows you to say that certain client-side URL params (e.g. gclid or other analytic params) can be ignored and still use the resource from the cache.
— Barry Pollard (@tunetheweb.com) September 26, 2025 at 11:57 AM
[image or embed]
Forum discussion at Bluesky.


