
We should have seen this coming, based on the number of reports that Google was submitting GET forms. But often, it is hard to validate those types of reports, due to people spoofing Googlebot and similar tactics. In any event, Google now admits to Crawling through HTML forms. Here are some things to know about this announcement in bullet form:
- For select menus, check boxes, and radio buttons on the form, Google will choose from among the values of the HTML.
- After gaining access to content pass the form, Google may or may not index that content
- You can block Googlebot from crawling your forms by excluding them in your robots.txt file
- Googlebot will only attempt to crawl GET forms
- Googlebot tries to avoid forms requesting userids, login, passwords, contact information and so on
- This should not impact PageRank
Matt Cutts of Google explains how this meets a need of so many webmasters that are clueless to SEO. In fact, from making the web more accessible, this new crawling technique rocks. But for SEOs and webmasters who want to block Google from accessing content, it will require some change on their part. I.e. they will have to restructure some of their sites to block Googlebot from crawling their forms.
The forum reaction is very mixed. We have threads at Sphinn, DigitalPoint Forums, Search Engine Watch Forums and WebmasterWorld.
Pros: Google can crawl places they haven't and index more of your content, which gives you more visibility. Cons: Pages you do not want indexed, might require you do more work to block them.
The big joke in WebmasterWorld is that Googlebot now has a credit card. For example, if it can submit forms, maybe Googlebot will start messing around with conversions. Obviously, it won't place orders but what about submit a simple form that you consider to be a conversion (i.e. like user agreements or more)? In fact, I found GoogleBot filling out this Google Checkout form to buy itself some WD40 (kidding of course):
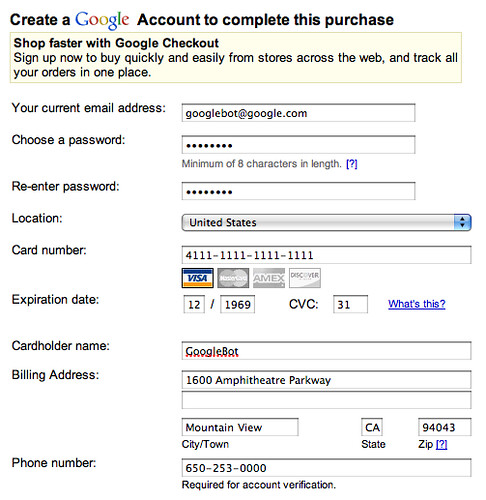
But you get the point.
Forum discussion at Sphinn, DigitalPoint Forums, Search Engine Watch Forums and WebmasterWorld.


