
Spotted via WebmasterWorld, a search for [Amazon s3 Forum]'s top two results actually come from Google's comparable cloud hosting service, Google App Engine. This is confusing, so let me step back.
Amazon is big into cloud computing services, one of their services includes Amazon S3, which is popular for image and video hosting. Now, if you search for Amazon S3's forum in Google, you'd think Google would show you the result for forums.aws.amazon.com, but no. Instead, Google shows you a cloned, apparently scrapped version, of that forum's content on Google's own cloud product named Google App Engine at appspot.com.
Here is a screen shot:
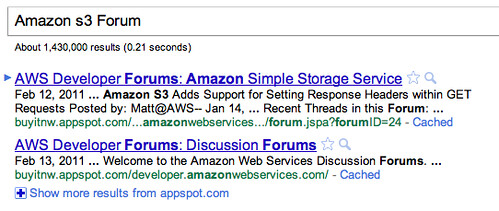
Compare the results on Amazon's domain to that on appspt.com:
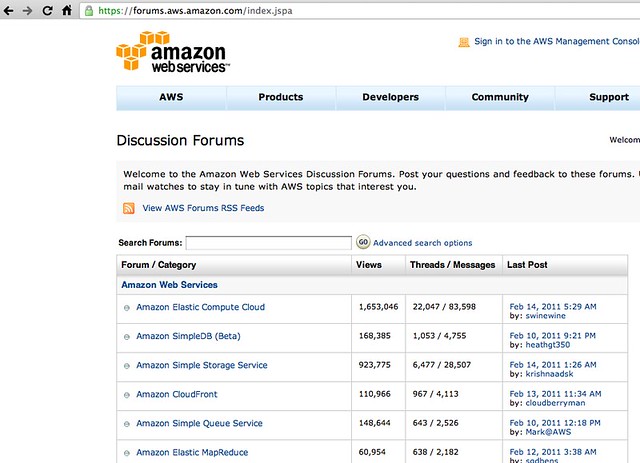
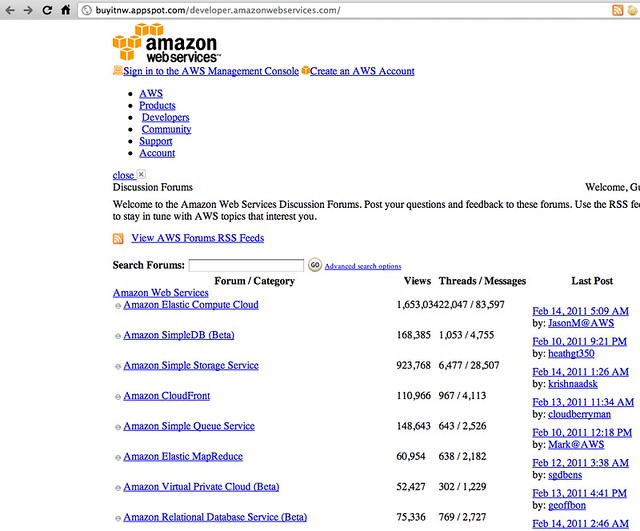
Don't they look very similar?
It is funny that Google recently made a big to-do over their scraper algorithm finding issues like this and then to see Amazon's content for their own cloud service being scraped and spammed onto Google's cloud service on Google.com's search results.
Why might this be happening? If you think about it, cloud services like these are used to house duplicate versions of your content for scalability. Maybe, just maybe, Google is more lenient with those services in the scraper algorithm.
Or maybe I have no clue what I am talking about - which is very likely here.
Forum discussion at WebmasterWorld.


