
Google recently announced a feature that they have implemented just a couple weeks ago in the search results named "Quick View." Quick View basically shows you a PDF in a web based PDF viewer on Google. It takes the PDF from the host, typically the owner of the PDF, and does all the conversion on the Google's server.
The neat part is that this feature gives you OCR for virtually all of the languages Google has translation for. I'll get to that in a bit, first let me show you a basic example of how Quick View works and then I'll show you the translation OCR.
A search for [w4] returns the IRS's web site with the PDF of a W-4 form.
When you click on the Quick View link in the search results, you get this page:
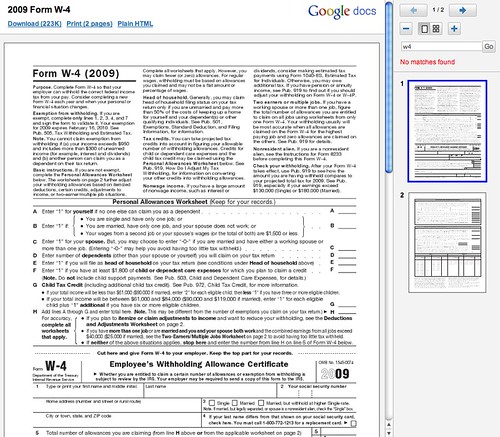
Yes, a neat view of the PDF, the ability to download the file, print it or convert it to plain html. A WebmasterWorld thread has webmasters who are not happy about this because this bypasses your site and you get no traffic benefit from this. Tedster explains:
So it looks like one more way that Google Search can distribute a site's content without requiring a direct visit to the site itself - and in this case, it's an entire document, not just a snippet. And the intention is to roll this out for other file format types, too.
To make things even worse, from a copyright standpoint is the OCR technology. I can upload a book, in almost any language, let Google index it as a PDF and then convert it to plain HTML and copy and paste from there.
For example, this hebrew book in Quick View looks like this:

If you click the "Plain HTML" link you are taken here where Google has OCRed the text into copy and paste friendly Hebrew. Pretty neat! Well, to some, not to those that might own the copyright on this text.
Forum discussion at WebmasterWorld.


